Machine Learning in Godot
This project is where three things I care about meet directly: RTS games, machine learning, and the space or sci-fi direction I have always liked most. Right now it works as a serious training ground for the day when I feel confident enough to build an actual RTS-style game based on reinforcement learning units.
The motivation behind it
I did not start this just to make agents move around a scene. I started it because I like machine learning, I like RTS games, and I want to understand how those two things could actually be integrated instead of only being talked about in vague AI terms.
The space and sci-fi direction was the natural choice because that aesthetic has always been close to my taste, and it also gives me a cleaner playground for arenas, movement, combat ideas and systems that feel compatible with RTS thinking. It is easier to scope for a solo developer than a huge content-heavy project, while still being close to what I actually enjoy.
I also genuinely appreciate Godot as an engine. I consider it an extraordinary project, and I have a lot of respect for the fact that something this capable exists as open source and completely free. Projects like this do not just help solo developers; they make experimentation financially and technically possible in the first place.
So part of this page is also a simple thank you to the people who built and maintain it. Without that kind of tool, this exact line of experimentation would be much harder for me to pursue at the same pace.
Right now the project is intentionally experimental. I am learning how to make agents fly, recover, navigate, race and behave inside controlled arenas. Later, the value of that learning is that I can carry it into something more strategic and more complete, with a better sense of how reinforcement learning units should behave inside an RTS-style game.
Why the training cycle takes so long
The brutal part of this work is time. One arena like this can take two or three months from start to stable result once I count environment work, reward design, debugging, retraining and all the failed attempts in between. By the time one version starts behaving well, I usually already know what I need to rethink in the next one.
That means every design choice matters more than it would in a typical gameplay prototype. If I define rewards badly, the agent learns nonsense for hours or sometimes days. If the environment is ambiguous, I do not just get bad gameplay, I get bad data and wasted compute time.
In practice I often try dozens of times before I get the reward calibration into a state that feels correct. And even then, I still have to repair bugs, edge cases and unstable interactions until the whole system stops collapsing under its own contradictions.
- Environment setup has to be stable enough for long runs.
- Reward shaping has to push the right behavior without inviting exploits.
- Bug fixing is part of training, because instability corrupts the lesson itself.
- Patience becomes part of the engineering process, not just a personality trait.
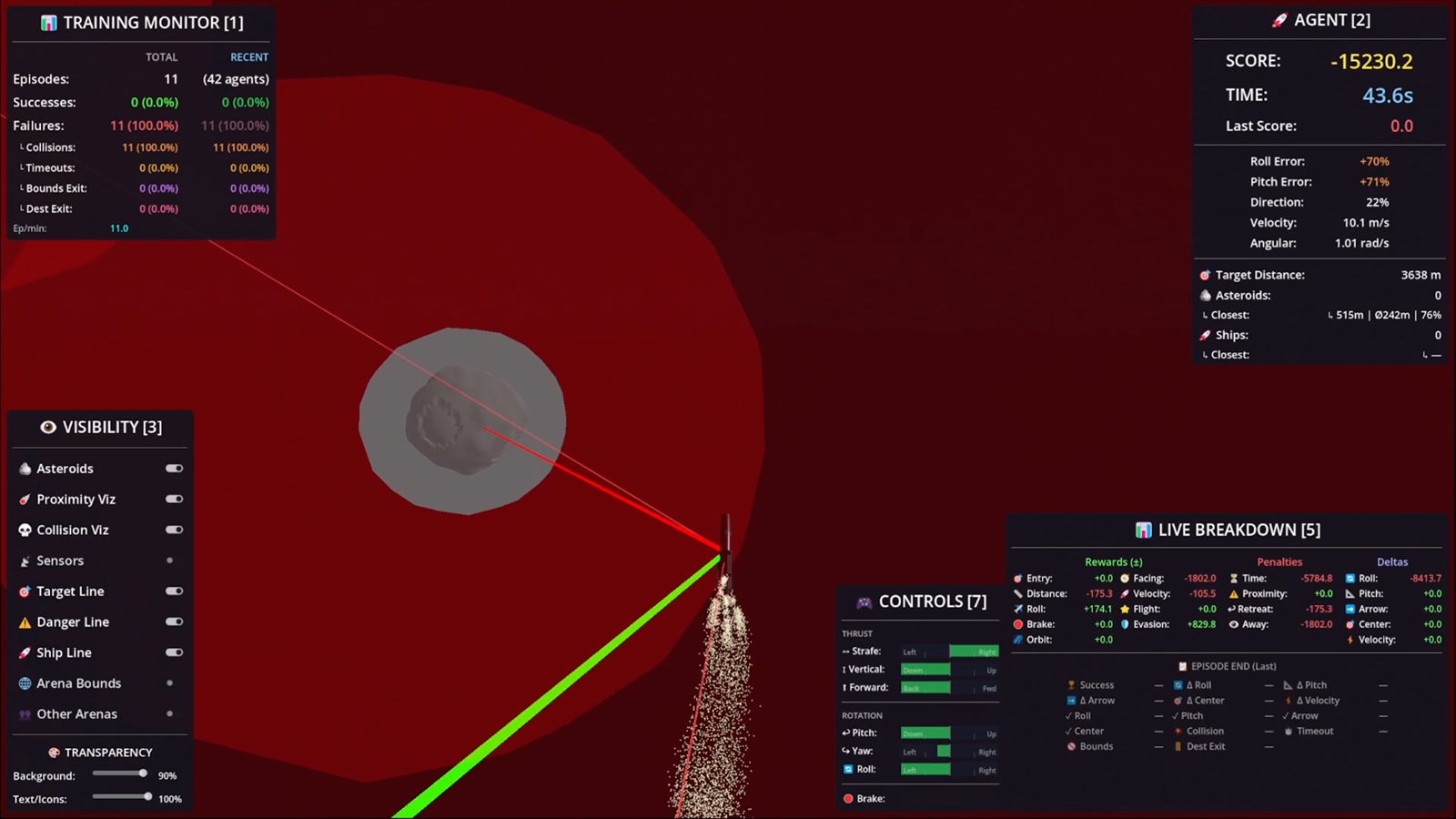

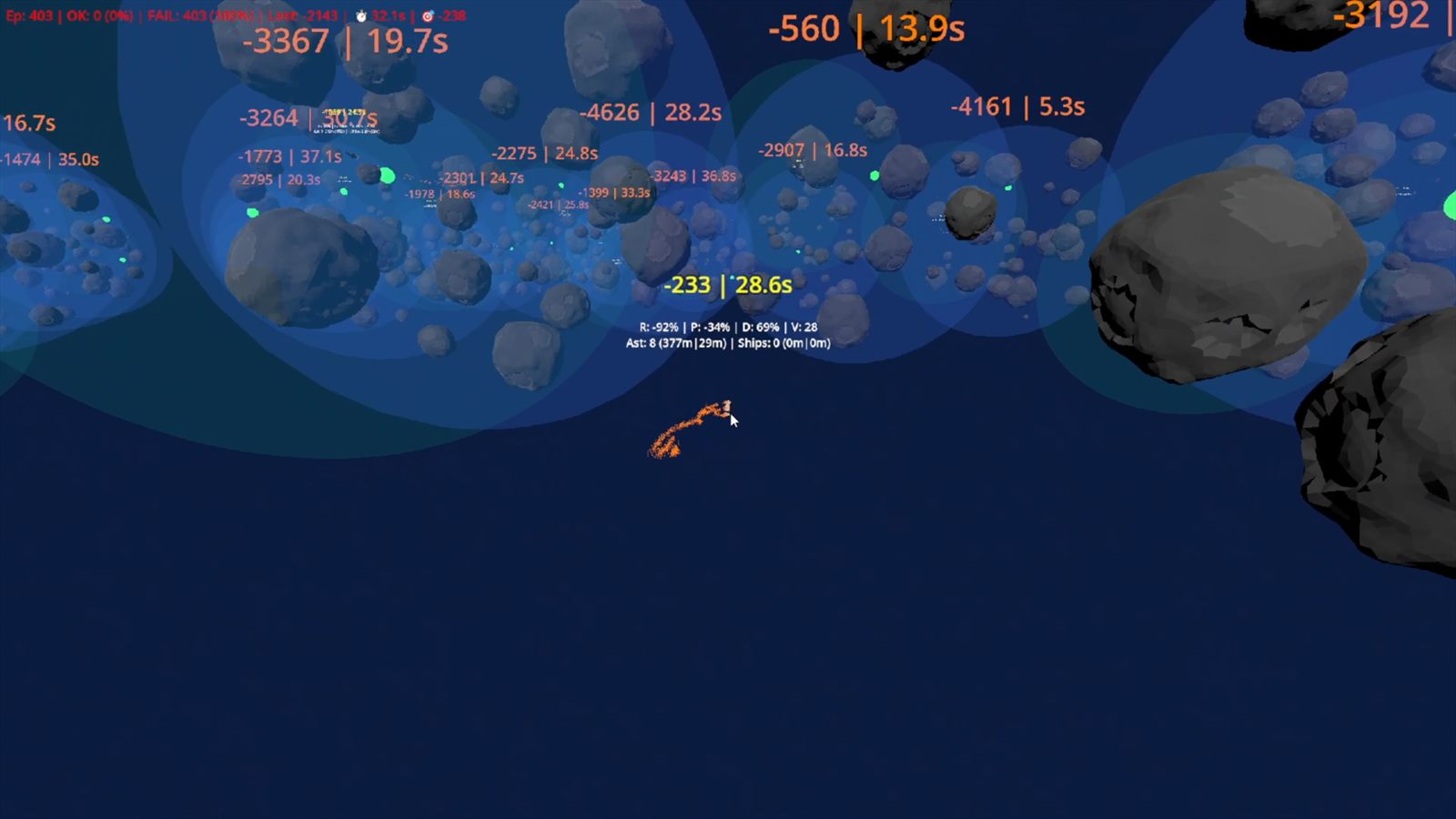

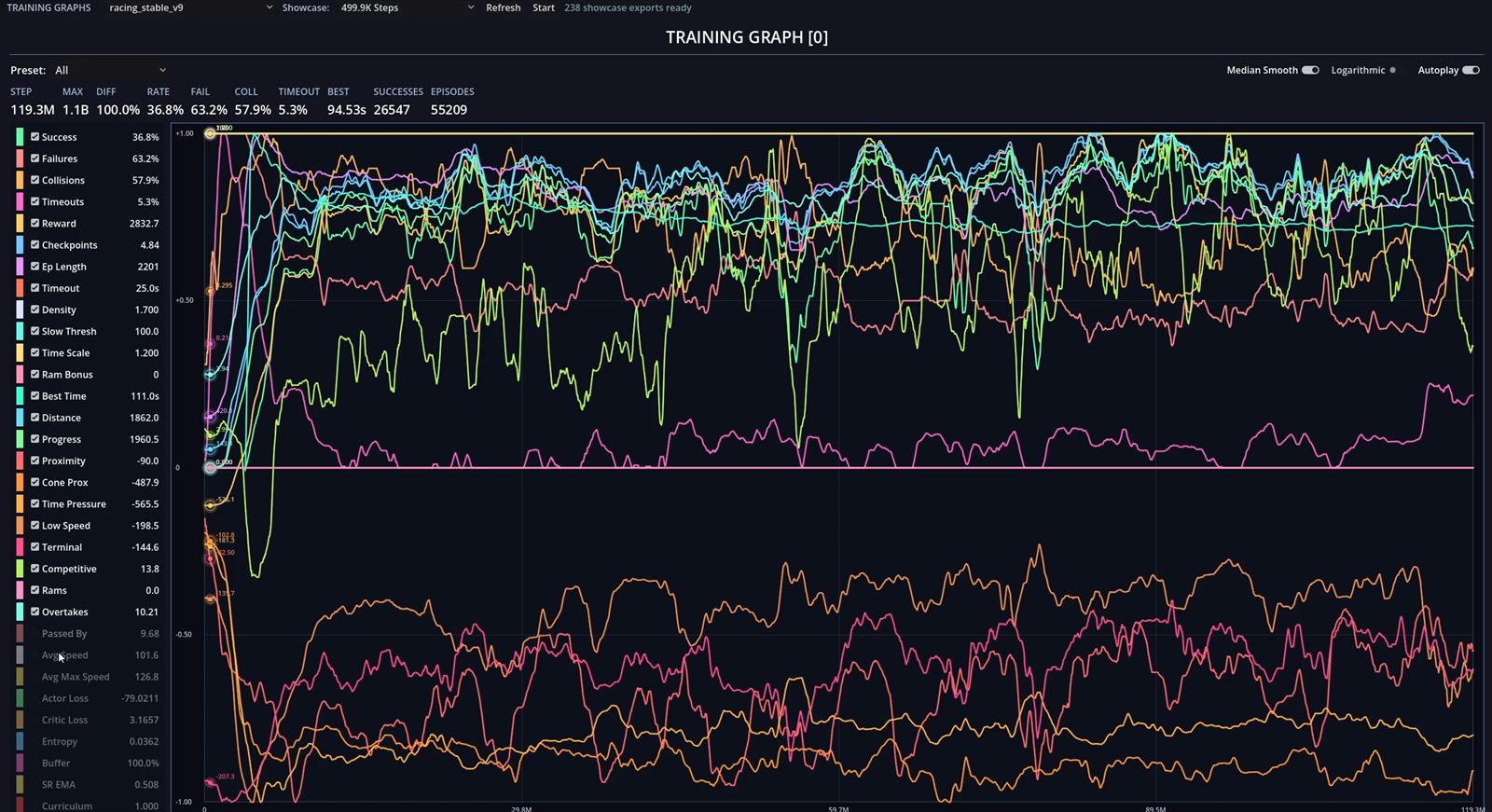
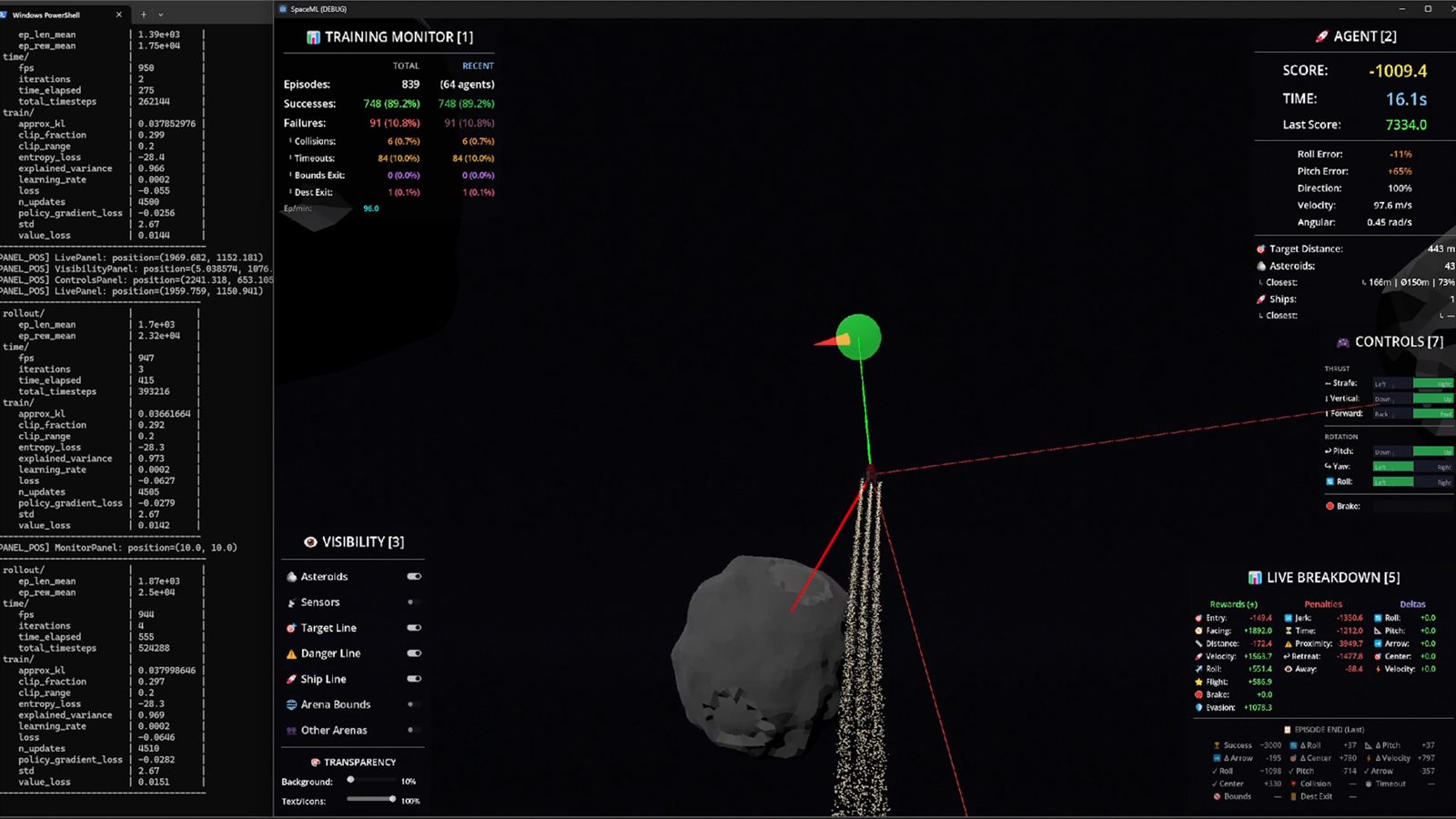
The project is teaching me how to think in delayed feedback loops, where a bad reward setup today can waste hours of computing power and a stable arena can become the foundation for the next serious step.
What I am actually learning from it
The biggest lesson so far is that reinforcement learning is not only about rewards. It is also about training stability. If the observation space is unclear, if the rewards fight each other, or if the run drifts into unstable behavior, the agent exposes the problem immediately.
That changed the way I work on these arenas. I care much more now about stable runs, readable feedback and repeatable behavior than about getting one lucky result that looks good in a clip.
I am learning how to define better objectives, how to read behavior together with logs and metrics, how to recalibrate rewards without breaking everything else, and how to keep pushing until the whole arena becomes stable enough to trust.
That matters to me because I do not want machine learning knowledge in isolation. I want machine learning knowledge that can survive real game design constraints and eventually support the kind of space RTS project I would actually want to build.
From navigation to racing
The first navigation training was much more basic. I used PPO, interrupted runs, changed rewards by hand, continued training and hoped the next adjustment would push the behavior in the right direction. It taught me the basics, but it was still close to a tutorial-style workflow.
The racing training is where I went deeper. I started with PPO there as well, then explored a TQC setup adapted from the SAC direction, and I put much more effort into the training loop itself instead of only the reward numbers.
That meant clearer observation space, live parameter calibration, real-time reward breakdowns, reward curriculum and stronger stability work. In the heavier training runs I also added things like entropy floors and gradient clipping because otherwise the training could drift or collapse.
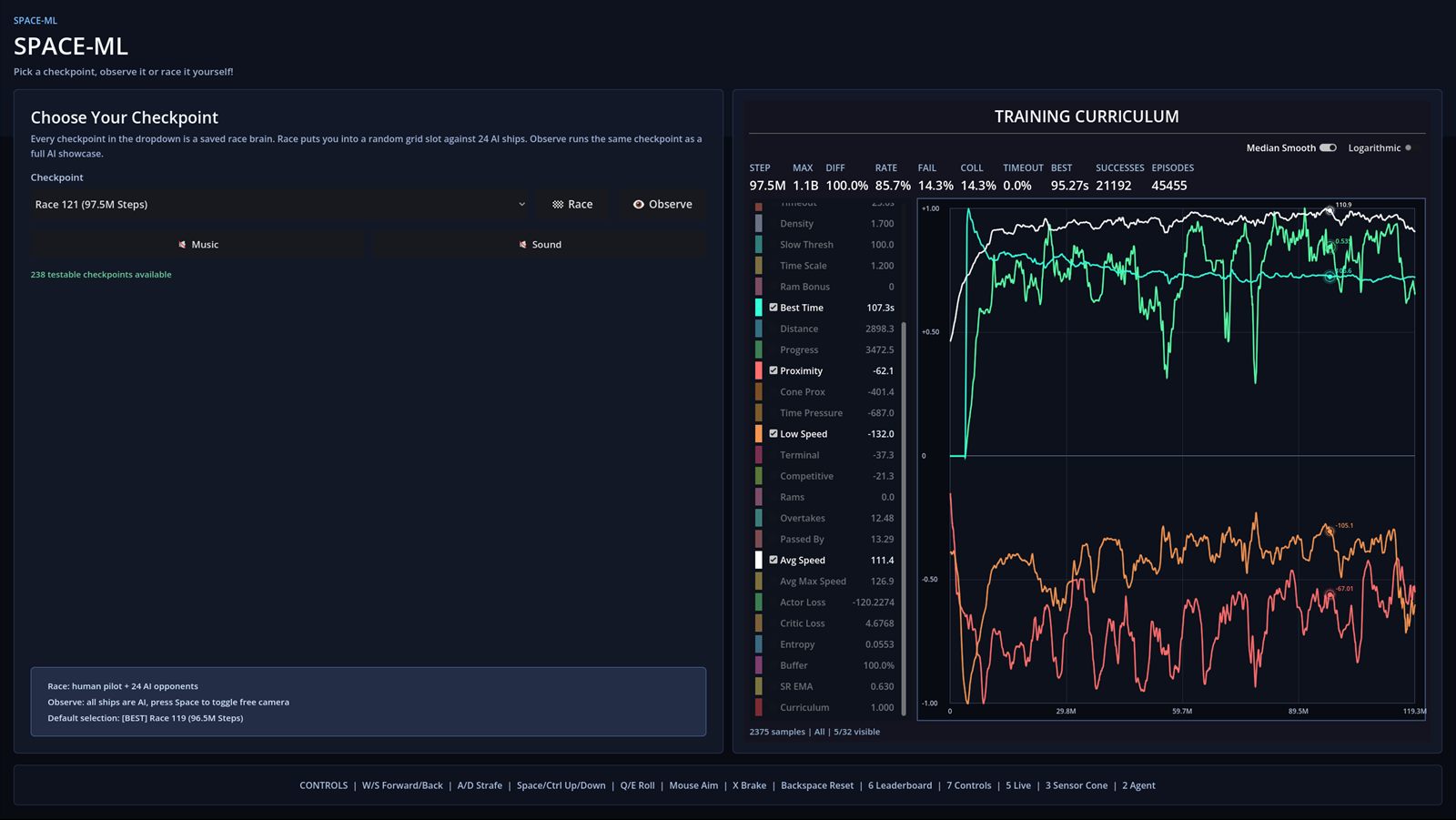
It is also where I added the graphs seriously into the workflow. That let me spend less time glued to the monitor trying to guess patterns from the ship movement and more time reading the training from the data itself.
The graphs also mattered for performance. If I did not need to stare at the rendered action all the time, I could use those resources for training and push more parallel environments instead.
That changed how I observed the project. I could wake up, check the graphs, compare the trends, and already have a good idea what kind of behavior I was about to see before I even watched the agents again.
That is probably the clearest difference between the two episodes. The first one taught me how this kind of system works. The second one taught me how to make it more stable, more readable and easier to evaluate without relying only on luck or constant visual monitoring.
Why I shipped a build
One important part of this project is the build itself. I did not want this to stay at the level of videos only. There are already plenty of machine learning videos on YouTube, so I wanted to offer something more direct: the chance to actually interact with the brains and checkpoints.
The build lets people test the project through all stages, not just watch the polished moments. I included the saved brains, the selectable checkpoints and the graph view in parallel, so it is possible to load a checkpoint, see where it sits in training history and then observe it or race it yourself.
The Windows executable may look a bit sketchy because I do not have a publisher signature on the .exe. That part is just a practical limitation, not something hidden in the build. The whole point was to make the experiments more accessible, not less.
For me this matters a lot more than releasing a passive showcase. I wanted the project to be something people can inspect, test and compare on their own, because that says more about the work than a cleaned-up edit ever could.
What's next: Combat training
The combat training is the next episode and it is still in progress. The goal there is not just to make ships move and shoot. The goal is to combine two brains that use the same observations for the same combat objective, but without the two brains knowing anything about each other directly.
In practice that means training the movement side and the turret side separately, then making them work together inside the same ship. One brain handles the engines and ship positioning, the other handles aiming and firing. It is the first time I am trying to combine two brains in the same way they would actually be combined in a real game.
I do not want to train both parts together from the start because the observations and the full decision space become too complex too fast. At that point the system either learns extremely slowly or learns very little that is useful.
For game development that matters a lot. You have to be efficient with training time, especially if you may end up needing dozens of AI behaviors. I cannot afford to spend too much time on each one, so splitting the problem into cleaner brains is the more practical path.